NOTE: This part requires some basic understanding of calculus.
These are just my solutions of the book Reinforcement Learning: An Introduction, all the credit for book goes to the authors and other contributors. Complete notes can be found here. If there are any problems with the solutions or you have some ideas ping me at bonde.yash97@gmail.com.
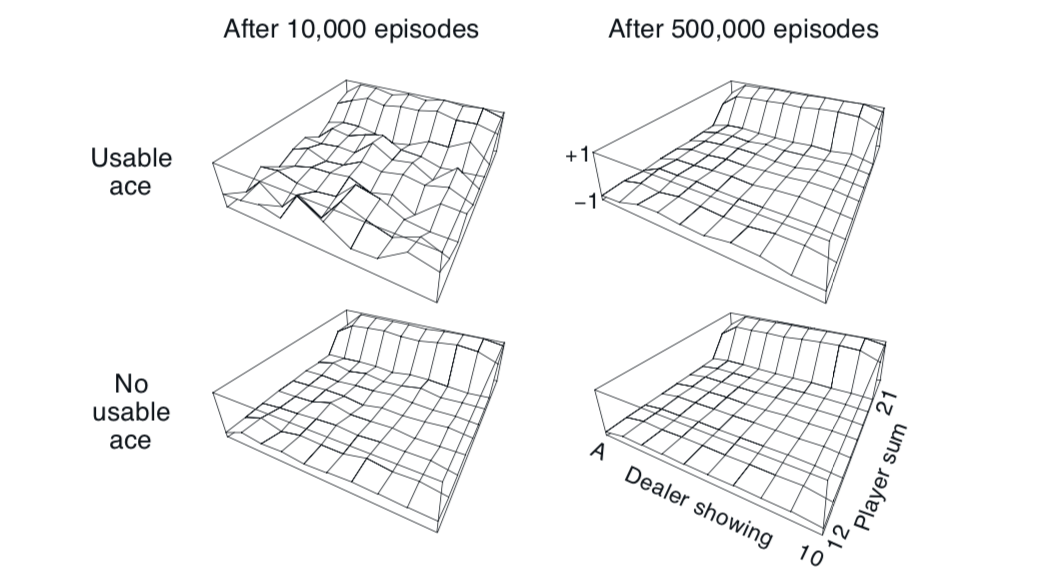
Blackjack approximate state value 5.1 - 5.2
5.1 Estimate Values
The value function jumps up for the last two rows in the rear because the value of the state at that moment is very high due to the sum of cards being in range. The dropoff occurs in the whole last row in the left because the dealer has shown an ace which can either be used as a or , thus it's confidence of victory is low. The frontmost values are higher in the upper diagrams as having a usable ace in the start is very beneficial.
5.2 Every-visit MC
With every visit MC the training cycles would be quicker as the average would be calculated over a larger reward base with discounts. But we are given that discount factor for this game and thus there will be no difference in the ETMC and FTMC in this game.
5.4 Improvements to MS-ES pseudo code
We need to add code for incremental averaging which gives us the following equation and it needs to be replaced in the pseudocode
Also note that the given pseudo code is first visit MC.
5.5 EV-MC and FV-MC estimated value
Looking at the algorithm for first visit we can see that and breaking out a quick script for every-visit we get value .
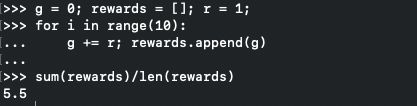
quick code
5.6 Value
The only change is that instead of counting the state visit we count the state, action visit i.e.
5.7 MSE increases
In the plot for Example 5.4 the error over all decreases but weighted sampling shows a slight rise and then decreases, question is why does this happen?
5.8 Why the jump?
In the plot for Example 5.4 the weight sampling increases and then decreases. This can happen because the value of is large, i.e. the bias is high. Though as the episodes progress the average reduces and so does the bias.
5.9 Change algorithm for incremental implementation
The simple change is the removal of list and getting value of as
5.10 Derive weight update rule
There are a few things here that represents the cumulative weight till now such that
5.11 Why off-policy MC control removes
Since is only allowed to change if and being deterministic we can say that we are safe to .